




1159 - ALGORITMOS DE MACHINE LEARNING PARA EL DESARROLLO DE UN MODELO PREDICTIVO DE MORTALIDAD E INGRESO EN UCI POR COVID-19
Hospital Universitario de Fuenlabrada, Fuenlabrada, España.
Objetivos: Desarrollar un modelo predictivo basado en algoritmos de machine learning para una variable combinada de ingreso en UCI y mortalidad en pacientes ingresados por COVID.
Métodos: Análisis retrospectivo de 5.379 registros de hospitalización por COVID en los periodos de febrero 2020-febrero 2023 en un hospital terciario, con datos extraídos de registros electrónicos y formularios: datos de filiación, fechas, antecedentes, datos clínicos y analíticos, así como estado de vacunación. En un preprocesado de datos, se seleccionaron solo las variables relativas a antecedentes y las adquiridas en las primeras horas de atención en urgencias. Se eliminaron las variables que tenían más de un 30% de valores perdidos, excepto proteína-C-reactiva y linfocitos en las que, por interés, se imputaron los valores perdidos. Las comorbilidades se codificaron de forma binaria. Las numéricas fueron sometidas a normalización. Se definió como variable desenlace una combinada de ingreso en UCI o fallecimiento, limitada a los primeros 60 días tras el ingreso. Los datos finales contenían 5.208 ingresos, sobre los que se produjeron 379 ingresos en UCI y 823 fallecimientos. Los modelos se crearon a partir de 19 variables: edad, sexo, antecedentes, Charlson, saturación O2 < 93%, proteína-C-reactiva y linfocitos en urgencias, estado de vacunación. Para el entrenamiento de los modelos, se utilizó el 80% en entrenamiento y el 20% para validación. Los modelos se ejecutaron usando código Python a través de la plataforma Kaggle, con uso de las librerías pandas, numpy, sklearn. Se realizó el entrenamiento de: regresión logística con regularizaciones L1, L2, random forest, support vector machines y redes neuronales, con ajuste de los parámetros según el caso.
Resultados: Los resultados de las métricas de rendimiento de los modelos entrenados se muestran en la Imagen 1. Se obtuvieron como métricas: recall (= sensibilidad), precision (= verdaderos positivos), f1-score y área bajo la curva ROC. Los modelos iniciales ofrecían sensibilidad inferior al 50% con una mejor detección de verdaderos positivos, en torno al 70%, a igualdad de área bajo la curva. Al tratarse de un modelo predictivo de mortalidad, se tomó la decisión clínica de determinar un umbral de decisión más bajo para potenciar la sensibilidad, en los modelos de regresión logística y random forest, invirtiendo la relación entre sensibilidad y verdaderos positivos. Los mejores modelos considerados (regresión logística y random forest) ofrecían una sensibilidad del 73-74%, con una tasa de verdaderos positivos del 56-57%, con un área bajo la curva de 0,87.
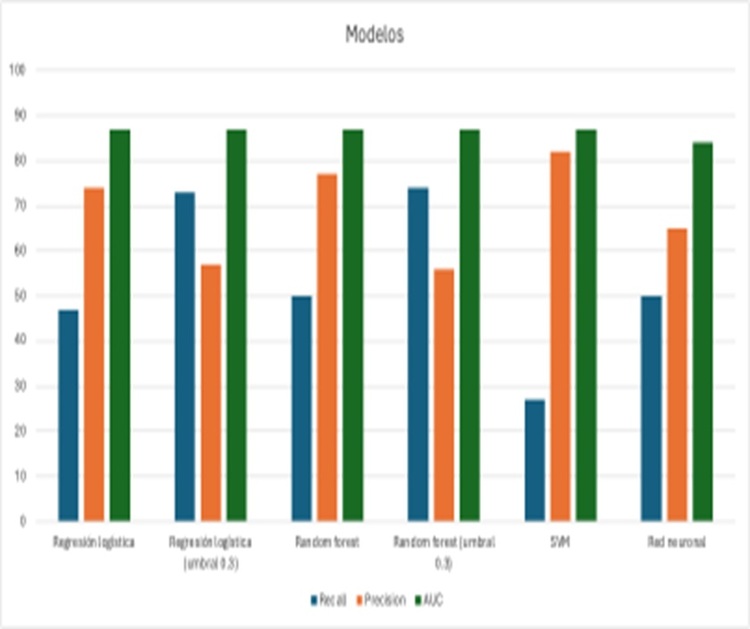
Conclusiones: El uso de modelos de machine learning es una herramienta cuyo desarrollo permite que ya sea incorporada a la práctica clínica y servir de soporte a la decisión. El conocimiento clínico y de los parámetros de los modelos, permite ajustar las métricas para potenciar cualidades del modelo acorde al objetivo clínico, como la sensibilidad. En este caso, conseguimos ajustar un modelo predictivo con un 74% de sensibilidad y 56% de verdaderos positivos y un área bajo la curva de 0,87, solo con 19 variables adquiridas en las primeras horas de atención del paciente.


